データマッチング
その ゴールデンレコード、 実は違った? Part 3 「データの中の真実」
マスターデータ管理(MDM)は「データの中の真実を見極める」訓練と言えます。 これ、とても真面目な話なんです! これは以前の記事(https://c-datalab.com/ja/blog/idr-matching_20240222)でも触れています。...
この記事では、特定のタイプのデータと、それがIDRでどのように使用できるかを探ります。まず、おさらいです: アイデンティティ・レゾリューション(IDR、データマッチング)とは何か、なぜそれを行うのか?
前回の記事(https://c-datalab.com/ja/blog/idr-matching_20231117)では、IDR(データマッチング)では少ないデータでより多くのことができること、完全性が全てではないこと、そしてMDM(マスターデータ管理)で日常的に行われている仮定には議論の余地があることをお話しました。 この記事では、特定のタイプのデータと、それがIDRでどのように使用できるかを探ります。
まず、おさらいです: アイデンティティ・レゾリューション(IDR、データマッチング)とは何か、なぜそれを行うのか?

アイデンティティ・レゾリューション(IDR)とは、人、ビジネス、場所、物など、何かのアイデンティティを理解することです。 すなわち、この実体が存在する背景(コンテキスト)は何かということです。 例えば、ある会社の最高経営責任者(CEO)は、その会社に対するその役割の一部として存在します。
つまり、ある存在(自然人)は、ある役割を介して別の存在(ビジネス)とつながっているのです。 そして、前にも説明したように、ある存在について知れば知るほど、将来その存在を認識(識別)するのに有利になると想定されます。
ニューヨーク州スカネアテレスに住むジェーン・スミス(46歳)がABC Brokerage LLCの最高財務責任者(CFO)であることを知っていて、「ジェーン・スミス」という名前がニューヨークで開催される「Women in Finance」の会合でスピーチしているのを見れば、両者が同一人物である可能性を計算し始めることができます。
IDRにおける名前の価値
以前、IDRにおける名前の価値についてお話しました。 IDRには公理として次のようなものがあります:
これはどういう意味でしょうか? 考えてみてください - 私たちがビジネスに名前を付けるとき、そのビジネスを一意に識別できるよう、他とは異なるものにしたいと考えます。 実際、ほとんどの会社名や商号の登録機関は、その管轄区域内での名前の十分な識別性を主張しています。 一方、人は通常、姓を共有し、多くの子供は親または他の先祖にちなんで名付けられます。そのため、個人のアイデンティティレゾリューション(B2C IDR)に関しては、誤検出を避けるためにちょっとした助けが必要になります。
そのうちのひとつについてお話します: 郵便番号です。
郵便番号
郵便番号はどこにでもあります。ほぼすべての国が郵便番号を使っており、地域によってさまざまな違いはあるものの、それらはすべて、地元の郵便局の郵便配達人が配達する地域を特定するために機能しています。
郵便番号はなぜ便利なのでしょうか?
郵便番号があることで、他の情報がいくつも出てきます。国によっては、都道府県や市区町村も出てきます。「少ないことは多いことだ」という観点からすると、これらのフィールドを完全性の計算から外すことができるので便利です。
つまり、郵便番号があれば、市町村や都道府県は必要ないという事になります。
しかし、郵便番号は単なる便利な指標や重要なデータポイント以上のものでもあります。
米国の2つの実例を見てみましょう:
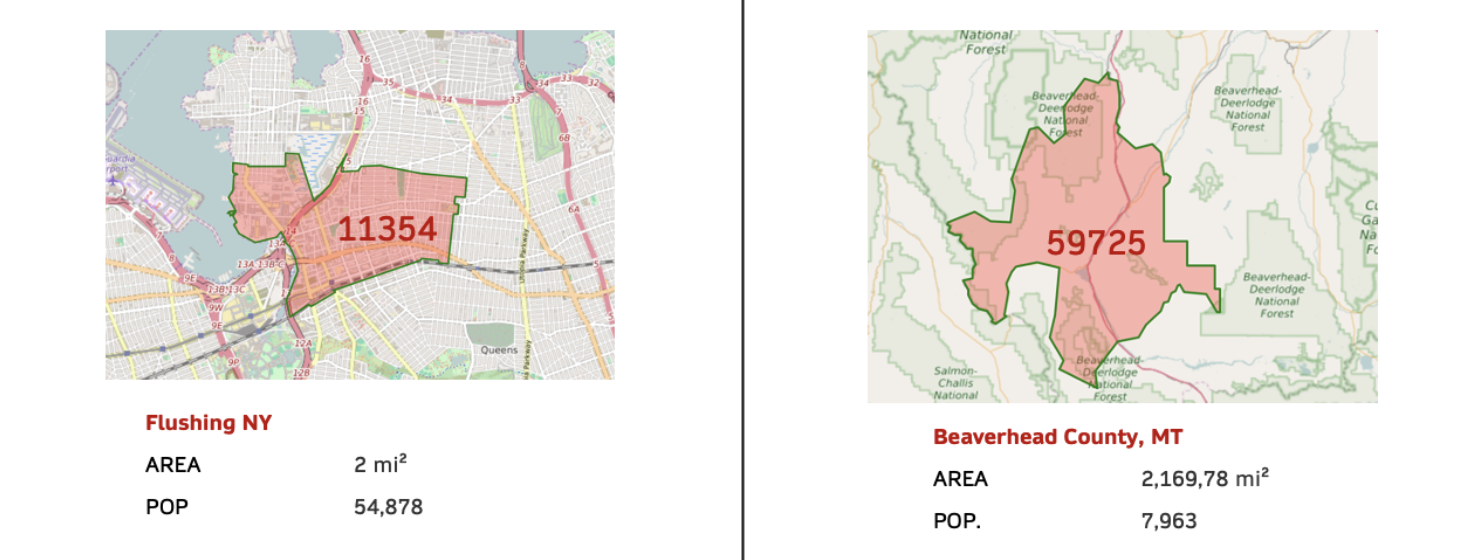
出典: https://www.unitedstateszipcodes.org
ニューヨーク市のフラッシングは、面積2平方マイル、人口約55,000人の規模です。一方、モンタナ州ビーバーヘッド郡の面積は200万マイル以上、人口は8,000人未満です。 なぜこれが重要なのか? 例を挙げてみましょう。
「ケイレブ・スミス」(よくあるアメリカ人の名前)という人物を探していて、名前と郵便番号しかわからないのに、ニューヨーク市フラッシングで一致する記録が見つかったとしたら、私たちは即座に「単なる偶然だろう」と答えるかもしれません。 しかし、モンタナ州ビーバーヘッド郡のケイレブ・スミスがヒットした場合、同一人物である可能性ははるかに高くなります。 つまり、郵便番号は非常に価値のある情報ですが、その価値(IDRの言葉を使えば予測力)は千差万別であるということです。
郵便番号もスコアの指標として使用できます。 スコアは、他の情報で一致するものが、同じ個人、企業、その他の事業体に対して類似している可能性がどの程度あるかを評価するのに役立ちます。
郵便番号から始めて、人口を面積で割って1平方マイルあたりの人口密度を求めることができます。そうすると:

これをすべての郵便番号について行い、最小スコアと最大スコア(便宜上「人口密度スコア」と呼ぶことにします)を取り、対数曲線配に配置し0から100まで測定することができます。基礎となるデータは非コンテキスト的(つまり、MDMプロセスで受け取ったものに依存しないので、参考資料として事前に組み立てることができます)であり、自由に利用できます。
・アメリカ:郵便番号による人口密度ランキングのサイト例
http://www.usa.com/rank/us--population-density--zip-code-rank.htm
また、人口密度スコアの威力を増すために追加要素を加えることも可能です。 例えば、アメリカのような多文化市場の場合、名前に「民族性推測ツール」を採用し、郵便番号別の民族性に関する米国国勢調査データと相互参照させます。 これによって、郵便番号59725の「ケンジ ナカムラ」は、ビーバーヘッド郡の人口の民族的多様性が非常に低いため、「ジョン スミス」よりも類似と判定される可能性がさらに低くなることがわかります。
・民族性推測ツールの例
https://pypi.org/project/ethnicolr/
・米国国勢調査データ
https://data.census.gov/map?q=zip+code+demographics
日本のような多様性に乏しい市場の場合、人口密度スコアの基本的なアプローチは依然として有効ですが、それを強化するために採用できるさまざまなアプローチや要素があります。 例えば、エリア内の商業アドレスの割合を示す指標や、基本的な名前の独自性スコアを採用することで、結果を大幅に絞り込むことができるのですが、これは将来の記事のテーマとします!
著者のご紹介

最高技術責任者 兼 最高データ責任者
ウオリック・マセウス(Warwick Matthews)
複雑なグローバルデータ、多言語MDM、アイデンティティ解決、「データサプライチェーン」システムの設計、構築、管理において15年以上の専門知識を有し、最高クラスの新システムの構築やサードパーティプラットフォームの統合に従事。 また、最近では大手企業の同意・プライバシー体制の構築にも携わっている。
米国、カナダ、オーストラリア、日本でデータチームを率いた経験があり、 最近では、ロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)および米国ナショナル・フットボール・リーグ(NFL)のアイデンティティ・データチームのリーダーとして従事。
アジア言語におけるビジネスIDデータ検証、言語間のヒューリスティック翻字解析、非構造化データのキュレーション、ビジネスから地理のIDデータ検証など、いくつかの分野における特許の共同保有者でもある。
©️Copyright Compliance Data Lab, Ltd. All rights reserved.
掲載内容の無断転載を禁じます。
マスターデータ管理(MDM)は「データの中の真実を見極める」訓練と言えます。 これ、とても真面目な話なんです! これは以前の記事(https://c-datalab.com/ja/blog/idr-matching_20240222)でも触れています。...
今回は、MDMとゴールデンレコードに関するシリーズ「そのゴールデンレコード、実は違った?」の4回目です。前回の記事では、MDMデータについて、そしてゴールデンレコードが良くも悪くも多くのデータ管理体制にとって重要であることについて、幅広く論じてきました。
テクノロジーに携わる方、あるいはデータを定期的に扱う職務に就いている方(最近ではほとんどの方ですね)であれば、「マスターデータ管理」、別名MDMという言葉を聞いたことがあるはずです。...