
データマッチング
その 「ゴールデンレコード」 実は違った・・・? Part 2:ゴールデンレコードとは何か、どのように機能するのか?
前回の記事(https://c-datalab.com/ja/blog/idr-matching_20240126)では、ゴールデンレコードは通常、マスターデ ータ管理(MDM)システムにおけるエンティティ(顧客など)の「ベストビュー」であることを説明しました。
マスターデータ管理(MDM)は「データの中の真実を見極める」訓練と言えます。 これ、とても真面目な話なんです! これは以前の記事(https://c-datalab.com/ja/blog/idr-matching_20240222)でも触れています。 この実証主義的アプローチは、望遠鏡を使って既知の物体を見つけ、それをよりよく理解するのに似ていると考えることができます。つまり、私たちは探しているものがそこにあることを知っており、それについてより多くの情報が必要なだけなのです。
マスターデータ管理(MDM)は「データの中の真実を見極める」訓練と言えます。 これ、とても真面目な話なんです!
これは以前の記事(https://c-datalab.com/ja/blog/idr-matching_20240222)でも触れています。
この実証主義的アプローチは、望遠鏡を使って既知の物体を見つけ、それをよりよく理解するのに似ていると考えることができます。つまり、私たちは探しているものがそこにあることを知っており、それについてより多くの情報が必要なだけなのです。

出典: Freepik
しかし、これが本当に私たちのデータの仕組みなのでしょうか?
私たちのMDMシステムは
- さまざまなフォーマット、出所、品質の大量のデータを受け取ります
- そのデータを分類し、クレンジングしようとします
- データを標準フォーマットに変換し、専用環境にロードします
- データを照合し、一貫したレコードにクラスタ化します
- これらのレコードを分析し、ゴールデンレコードで使用する最適な部分を選択します
- そのゴールデンレコードを使用して、データ要求を満たします
従来のMDMの常識は、解像度を向上させるためにデータポイントを増やすことです - 知れば知るほど、その人についてより多くのことがわかります。
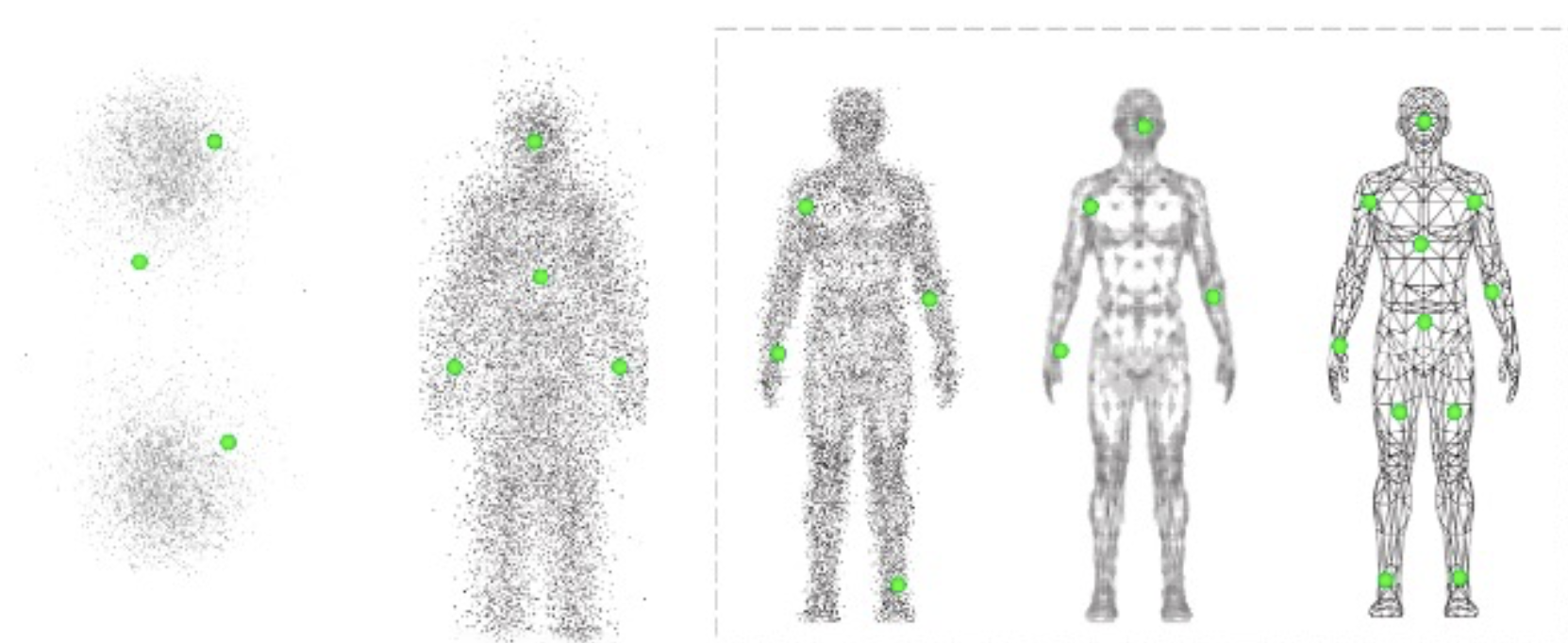
新しいデータをエンティティのレコードにマッチさせると、そのデータについてより深く理解することができます。
ここで質問です:私たちはどの時点で、どのような実体(人、場所、物)を扱っているのかを実際に知ることができるのでしょうか? (ヒント:わからないんです)。

データはいつ "本物 "になるのでしょう?
MDMシステムは、共有された(または少なくとも類似した)属性に基づいてレコードをクラスタリングし、フィルタリングすることで、エンティティに関する真実が得られるという前提で機能します。 つまり、大量のレコードがあり、それらを顧客ファイルと正確にマッチングさせれば、それらの顧客についてより多くのことを知る(少なくともより多くのデータを持つ)ことになる可能性が高まります。
一般的なルールとして、これはアウトプットとして良いレコードを生成する...しかし、実際にはデータがどのように機能するかはまったくわかりません。 現実に、私たちのシステムは、バラバラのベクトルを介して私たちのシステムにロードされたレコードに含まれる一握りの属性を受け取り、照合し、そしてその背後にある個人/企業について仮定します。 レコード#1に個人名と電子メールアドレスと思われるものがあり、同じ電子メールアドレスと住所を含むレコード#2とマッチングさせた場合、私たちはその人物について3つの情報を得たと結論づけます。
そのプロセスは実証主義的(真実を発見する)ではなく、実際には構成主義的(真実を構築する)になります。私たちの主観的結論だけが実証主義的であり、つまり私たちは実在する人物についてより多くを学んでいると考えています。

人間として、私たちはデータの裏に何かがあると信じる必要があります。
現実には、MDMシステムはデータ・ポイントをつないでいるにすぎず、私たち人間は、つながったデータセットが客観的に実在するエンティティのストーリーを語っていると結論づけているにすぎません。
別の言い方をすれば、構成主義的真実の原則は、ある実体に関する「真実」は文脈に左右されるということです。 言い換えれば、今あるデータで必要なことができるのであれば、理論的に何が客観的真実であるかは問題にならないということです。

映画『ア・フュー・グッドメン』で、トム・クルーズ演じるダニエル・カフィーがジョアン・ギャロウェイ(デミ・ムーア)に憤慨してこう叫んだシーンを覚えていますでしょうか:
「僕が何を信じているかは関係ない。重要なのは、僕が何を証明できるかだけだ!」。
これは構成主義的アイデンティティのようなもので、「完璧な」レコードという理論的定義に照らして評価するのではなく、受け取ったままに評価するのです。
「確かにそれは良いことです」が、「現実の企業データにおける真実はどうなんですか? そんなに複雑なことではないですよね!」
以前の記事で「裏付け(Corroboration)」という概念について触れましたが、これはいわゆる情報源の数と量です(例えば、4つの情報源のうち3つが、ある人物の住所が同じであるなど)。「複数化」とも呼ばれます。裏付け/複数化には、データが正確である確率を向上させるという、「真実」を立証するメリットと基礎があります。
あなたのビジネスは、おそらく顧客から直接または間接的にデータを受け取っているはずですが、なぜそのレコードが正確でないのでしょうか?
まず、顧客は自分が望む情報しか我々に見せてくれません。そして、今日の消費者(特にオンライン消費者)は、ペルソナの多様性を本能的に理解するようになってきています。 そのため、顧客は必ずしも常に本当のことを言うとは限りません。実例として、私は生年月日を尋ねるウェブサイトで、自分の生年月日を偽っています。 サイバー犯罪者にとって生年月日は非常に貴重な情報なので、私は軽々しく自分の生年月日を教えません。
しかし、それ以上に、技術的な進歩があったとしても、データの収集、照合、利用は依然として人の手によるものです。 人は名前を聞き間違えたり、タイプミスをしたり、レコードを混同したり、間違ったファイルを読み込んだりします。

ニューヨークのコーヒーショップで、オーストラリア訛りと "Warwick "
という名前を持つこと… これこそがMDMの大きな課題です!
名作TVシリーズ『ギルモア・ガールズ』[https://en.wikipedia.org/wiki/Gilmore_Girls]を考えてみましょう。この番組の2人の主人公は、ローレライ・ギルモアと彼女の10代の娘ローリーです。 ただし、ローリーの本名は...ローレライ・ギルモアです。 そして、この番組をよく知る人のために、ローリーの父方の曾祖母である3人目の「ローレライ・ギルモア」が存在します。 もし私たちのビジネスが、37 Maple Street Stars Hollowにある「ローレライ・ギルモア」の単一の記録を作成し、ローリーと母親のローレライの両方から発信されたデータを混同して作成した場合、そのデータは不正確であり、したがって「真実」ではなくなるのでしょうか?客観的(実証的)には答えは「イエス」ですが、構成論的には「誰も気にしない!」となります。
この点については、第4弾と最終回で「目的に合ったアイデンティティ」について掘り下げる際に、さらに詳しく説明することにします。
(裏付けの弊害のひとつとして、この例における「真実」では、ローリーと彼女の母親からのデータが混同している可能性があるという点です)。
「多ければ多いほど良い」という考え方の類似として、「三角測量の誤り」と呼ばれるものがります。 MDMシステムは、IDR(マッチング)機能を使用して、複数の異なるソースからゴールデンレコードに更なるデータを追加しようとします。 これらの異なるソースから同じ事実を「三角測量」することで、あるエンティティの真実である可能性が高いものを割り出すことができます。 単純な例は電話番号です。ある連絡先の同じ住所が3、4回確認された場合、それが正しい可能性は高いということですよね?
実はそうではないかもしれません。 まず、ある情報源から同じデータを一定期間にわたって受け取ったということは、その情報源によって何度も確認されたということかもしれません......あるいは(もっと可能性が高いのは)同じデータが4回送られてきて、データ転送が行われたときに「更新日」が記録されたということかもしれません。
より危険なのは、データが自己言及的であることです。 つまり、データは複数の情報源からもたらされていますが、実際には単一の情報源からもたらされているということです。これは様々な理由で起こりうるのですが、単純なものとしては、A社とデータ・パートナーが同じMDMテクノロジーを共有しており、それが同じデータプロバイダ(エクスペリアン社、ダンアンドブラッドストリート社、アクシオム社、エクイファックス社など)に紐づいていることが挙げられます。 双方が同じソースからデータ強化にお金を払っている場合、どちらかがその事実に気づかないままレコードが統合され始めるリスクはゼロではありません。
さらに悪いことに、この記事の著者は2人とも、データプロバイダによって取得されたデータが自己参照的であっただけでなく、調査した結果、実は我々から発信されたものであることが判明しました...言い換えれば、我々は自分たちのデータを売り戻されていた、という状況に陥ったことがあるのです! ユビキタス・リアルタイム・データ・キャプチャの時代において、これはMDMシステムにとって増大するリスクです(業界には、一般に認識されている以上に多くのこのようなケースが存在します)。
「作業上の真実」を確立するために、もうひとつ考えておきたいことがあります。データを無作為にサンプリングし、「正確」とはどのようなものかについての正式な定義に従って、その正確性を調査するのです。サンプリングは、いくつかの基本原則を守れば、大きな負担をかけて、超高度に洗練されたものにする必要はありません:
最後にひとつだけお伝えしておきます:何が「黄金(ゴールデン)」とみなされるかが人それぞれであるように、品質の捉え方も人それぞれです。例えば、ある企業の営業担当者にとっては正確な情報も、その企業の業務担当者やエンジニアの観点からは「正確」とは言えない場合もあるということです。
次回は、MDMにおける 「良い 」とは何かという新しい見解と、その新しいパラダイムを実現するためのシステムやプロセスの構築方法を提案する前に、実証主義的なゴールデンレコード体制の究極的な限界について掘り下げていきます。
著者のご紹介
ウオリック・マセウス / ジョン・ニコディモ 共著

ウオリック・マセウス(Warwick Matthews)
最高技術責任者 兼 最高データ責任者
複雑なグローバルデータ、多言語MDM、アイデンティティ解決、「データサプライチェーン」システムの設計、構築、管理において15年以上の専門知識を有し、最高クラスの新システムの構築やサードパーティプラットフォームの統合に従事。 また、最近では大手企業の同意・プライバシー体制の構築にも携わっている。
米国、カナダ、オーストラリア、日本でデータチームを率いた経験があり、 最近では、ロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)および米国ナショナル・フットボール・リーグ(NFL)のアイデンティティ・データチームのリーダーとして従事。
アジア言語におけるビジネスIDデータ検証、言語間のヒューリスティック翻字解析、非構造化データのキュレーション、ビジネスから地理のIDデータ検証など、いくつかの分野における特許の共同保有者でもある。

ジョン ・ ニコディモ ( John Nicodemo )
NFLシニアコンサルタント
アメリカ国内でも、最も優れたデータ・リーダーの一人であり、アメリカ、カナダ、そして世界各地のデータ・コンテンツ・チームのマネジメントに従事。 米国ダン・アンド・ブラッドストリートをはじめロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)など、大手企業でデータ管理チームを率い、世界トップクラスの企業からグローバルデータ戦略やソリューションに関する依頼を受ける。 現在は、米国ナショナル・フットボール・リーグ(NFL)のシニアコンサルタントとしてファン・インテリジェンスとデータ共有のエコシステムを全面的に刷新する際のアドバイザーとして従事している。
©️Copyright Compliance Data Lab, Ltd. All rights reserved.
掲載内容の無断転載を禁じます。
前回の記事(https://c-datalab.com/ja/blog/idr-matching_20240126)では、ゴールデンレコードは通常、マスターデ ータ管理(MDM)システムにおけるエンティティ(顧客など)の「ベストビュー」であることを説明しました。
これまで4回にわたり、MDM(マスターデータマネージメント)、データの真実、ゴールデンレコードに基づくシステムの正当性と欠点について述べてきました。 また、ほとんどのゴールデンレコードが持つ実証主義的な性質についても触れてきました。
今回は、MDMとゴールデンレコードに関するシリーズ「そのゴールデンレコード、実は違った?」の4回目です。前回の記事では、MDMデータについて、そしてゴールデンレコードが良くも悪くも多くのデータ管理体制にとって重要であることについて、幅広く論じてきました。