データマッチング
その ゴールデンレコード、 実は違った? Part 4 「ゴールデンレコードの限界」
今回は、MDMとゴールデンレコードに関するシリーズ「そのゴールデンレコード、実は違った?」の4回目です。前回の記事では、MDMデータについて、そしてゴールデンレコードが良くも悪くも多くのデータ管理体制にとって重要であることについて、幅広く論じてきました。
これまで4回にわたり、MDM(マスターデータマネージメント)、データの真実、ゴールデンレコードに基づくシステムの正当性と欠点について述べてきました。 また、ほとんどのゴールデンレコードが持つ実証主義的な性質についても触れてきました。
これまで4回にわたり、MDM(マスターデータマネージメント)、データの真実、ゴールデンレコードに基づくシステムの正当性と欠点について述べてきました。
また、ほとんどのゴールデンレコードが持つ実証主義的な性質についても触れてきました。これは つまり、実在するエンティティ(例:人)の真実を知ることが目的であり、そのエンティティについてすべてを知ることが理想的な結果であるという世界観に基づいています。

アルバート・アインシュタインは、物体を光速まで加速するのに必要なエネルギーは、やがて無限大に近づくほど巨大になることを教えてくれました。 実はゴールデンレコードにおいても同様の現象が見られます:
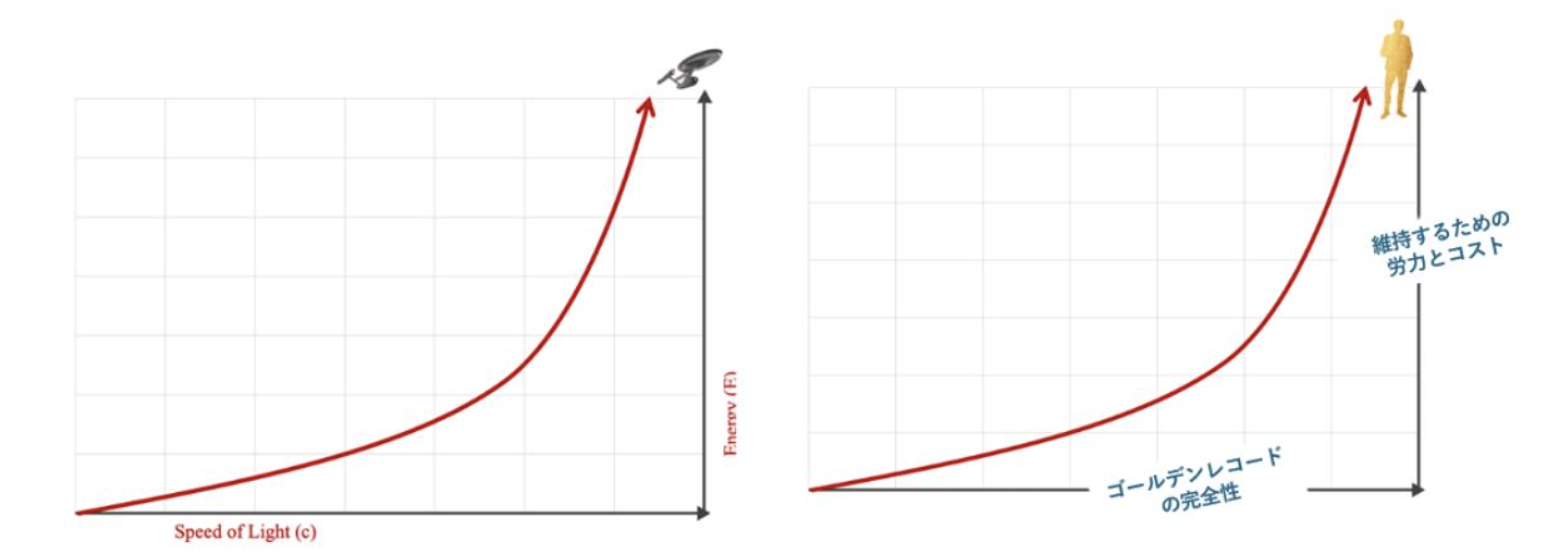
物理学の加速度と同じように、「完璧な 」ゴールデンレコードを保持するために必要なエネルギー(時間と労力とコスト)は、やがて無限大に近づいていきます
「完璧な」レコードを組み立て、作成するために費やされる時間と労力も、ある時点から無限大に近づき始め、つまり持続不可能になります。 実際、MDMデータを「完璧からの距離」で測定する必要は無く、返って逆効果であるというのが我々の主張です。
そこで我々は代替案を提案します:目的に適したID (F4P ID)です。

F4P IDの指針は以下の通りです:
- すべてを保存する
- 賢く一致させる
- すべてをリンクする
- 優先ルールを可能な限り最新のステップに移す
- 多様性は不整合ではない
ETLは、フィルタリング、絞り込み、重複排除のためのものであってはなりません。 昔と違い、今はストレージも安価で、既製の技術で数百万(または数十億)レコードのファイルを簡単に検索・取得することができます。 ETLデータハイジーンは、基本的には追加的なプロセスであるべきです。つまり、例えば名前をクレンジングするとき、そのクレンジングされた名前をn個の追加ビューとして追加するのであって、「生」のデータを置き換えているわけではありません。 簡単な例として、句読点を削除しても、余分なカンマやスペース、奇妙なアクセント記号など、元の句読点はそのまま残ります。 この 「ランド・アンド・ストア」アプローチは、現在ベストプラクティスとなっているデータレイクハウスの枠組みにも沿っています。

我々は、単純化された決定論的マッチング(MDM マッチングシステムの90%を占める)から移行する必要があります。 これは、AIを加えることで解決できる事ではありません。 AIはエンティティのマッチングとIDの解決においては非常に役立ちますが、すべてを解決できるものではありません。 その理由は、複雑であり、この記事の範囲を超えてしまうためここでは触れないようにします。
我々はあらゆるものにエンティティを見いだし、そのようにデータを保存します。 すべてのものはリンクされたレコードセットを介して接続され、同時にデータ内の時間も管理します。

入力されたデータに対して適格性ロジックを実行するのではなく、ランディングされたデータとして保存します(上記参照)。 優先順位ルールは、保存のためのゴールデンレコードを構築するために実行されるのではなく、消費するユースケースで必要とされる最適なビューを生成するために使用されます。
不整合はMDMシステム(そして一般的な研究開発チーム)にとって忌むべきものである、という考えはもう古いです。データ製品に固有のばらつきがあることは、実は不整合ではなく、また、多くの場合悪いことではないのです。 別の言い方をすれば、多様性とは、わずかに異なる質問に対して異なる答えを持つこと(良いこと)であり、一方不整合とは、同じ質問に対して異なる答えを持つこと(とても、とても悪いこと)です。

記録のばらつき=悪いというわけではありません
すべてを保存し、一元化された記録からアクセスできるようになれば、MDMデータのパターンやシグナルが見えてきます。 例えば、東京の渋谷区での定期的なアクティビティと北海道のニセコでのアクティビティが交互に表示される場合、もっと深く調べてみると、ニセコでのシグナルは12月から2月にかけてのみ発生していることがわかるかもしれません。
F4Pが絶対にそうではないことから始めましょう: アイデンティティに対するこの構成主義的アプローチは、エンティティ(人、場所、組織、出来事)の定義が本質的に不安定であったり混沌としていたりすることを意味するものではありません。我々は、MDMシステムでエンティティを作成するために単一の経路を使用し、その間マッチングアルゴリズムは一貫して使用されます。
異なるのは、すべてのユースケースに同時に対応する1つのマスターレコードを目指さないということです。
構成主義的なF4P IDモデルをどこまで推し進めるかも、定かではありません。説明のために、まず単純なもの、そしてより高度なものを見てみましょう。
単純なF4Pのユースケースでは、MDMプラットフォームのIDR(マッチング)プロセスを使って、中央の 「リンクエンティティ」を中心にソースレコードを繋げます。 このエンティティ自体は、主に元のソースレコードを指し示すIDとメタデータの集合体であり、この仮想システムでは保持され、容易にアクセスできます。
この仮想システムでは、標準化されたデータモデルが作成され使用されますが、それらは状況に沿ったものであり、出力、つまり特定のユースケースに必要なデータに合わせて調整されます。 MDMシステムの優先順位ルールは、そのユースケースを反映したものになります。 例えば、あるユースケース(マーケティング・キャンペーン等)が有効な送付先住所を必要とする場合、私たちはソース・データを使用し、キャンペーン資料が届く可能性が最も高いルールを定義します。 一方、郵便番号を使用して特定の地点(ショッピングモールなど)周辺の顧客の集中度を計算するユースケースの場合は、リンクされたソースレコードの住所データから代替郵便番号を利用することがあります。
このモデルは非常につながりが強く、我々が公開しているデータは状況に沿ったものです
もちろん、これらが同じである可能性は非常に高いのですが、同じである必要はありません。 良い例として、(その人が好む「発送先」の住所であるため)マーケティングのユースケースには勤務先の住所を使い、近隣分析には自宅の住所を使うような場合です。 もちろん、まともなゴールデンレコードであれば、これら2つの情報を持っていると主張することは可能でしょう。 また、ユースケースがもう少し特殊だったらどうでしょう? 重要なのは、この構成主義的なF4P IDアプローチでは、データがどのように使われるかを想定しないということです。
高度な目的に適したID(Fit-for-purpose ID)の例として、グラフデータベースを使用して、接続されたソースエンティティを格納し、一致する頂点の周囲に「円」を描くことによってMDMを実行します。 エッジはベースとなるつながりの強さを保存し、サークル(実際には、コンテキスト頂点からのハブおよびスポーク1:m接続のようなもの)も重み付けされ、スコア化されます。
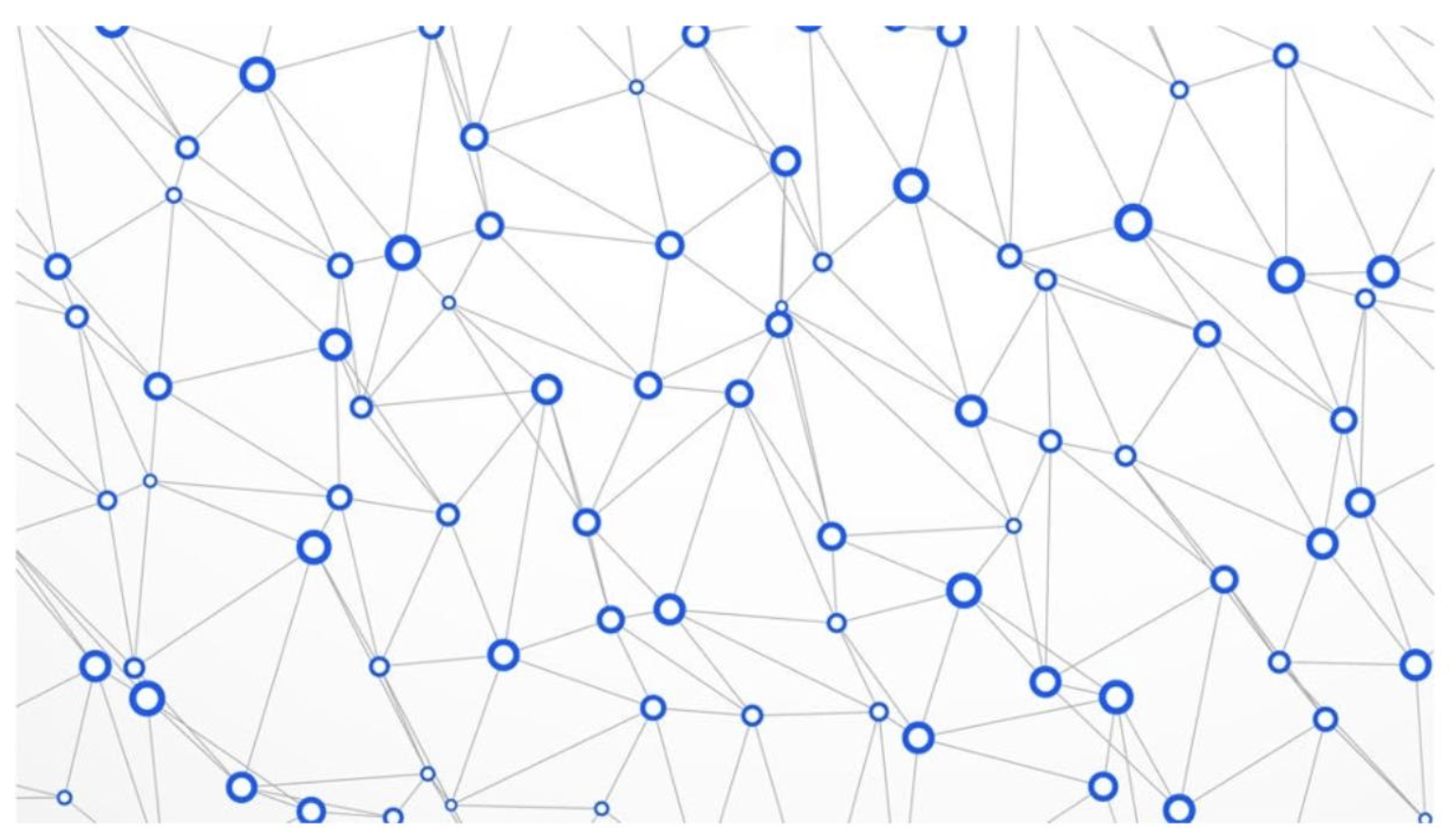
グラフ・データ・モデルは、強力で柔軟なビューと関連付けを作成することができます
つまり、エンティティ(人、場所、組織、イベントなど)の定義は、これらの複雑なグラフクエリの関数であり、固定されておらず、非常に興味深い順列や組み合わせを生成することができます。 多くのユースケースではやりすぎかもしれないのですが、不正検知、コンプライアンス、大規模な1:1パーソナライゼーションなどの特殊な分野では、信じられないほどの洞察力を発揮します。
また、シンプルなF4Pアプローチと高度なF4Pアプローチ(そしてゴールデンレコードパラダイムも)を同時に使用することは非常に有効です。
この5回に渡るシリーズでは、MDM、アイデンティティ、そしてゴールデンレコードの普及体制にまつわるいくつかの重要な問題を提起することに努めてきました。 この最終回では、新しいMDMアプローチの可能性をいくつか紹介しましたが、我々は「ただ水を加えるだけ」という杓子定規な解決策を提供することを目的としているのではなく、むしろこの分野での思考や質問、さらには意見の相違を促すことを目的としています。
我々が所属するコンプライアンス・データラボ株式会社やまた大手であるNFL等は、これらの問題に対するエキサイティングな解決策に取り組んでおり、近い将来、これらの進捗状況をまた皆様と共有できることを楽しみにしています。
著者のご紹介
ウオリック・マセウス / ジョン・ニコディモ 共著

ウオリック・マセウス(Warwick Matthews)
最高技術責任者 兼 最高データ責任者
複雑なグローバルデータ、多言語MDM、アイデンティティ解決、「データサプライチェーン」システムの設計、構築、管理において15年以上の専門知識を有し、最高クラスの新システムの構築やサードパーティプラットフォームの統合に従事。 また、最近では大手企業の同意・プライバシー体制の構築にも携わっている。
米国、カナダ、オーストラリア、日本でデータチームを率いた経験があり、 最近では、ロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)および米国ナショナル・フットボール・リーグ(NFL)のアイデンティティ・データチームのリーダーとして従事。
アジア言語におけるビジネスIDデータ検証、言語間のヒューリスティック翻字解析、非構造化データのキュレーション、ビジネスから地理のIDデータ検証など、いくつかの分野における特許の共同保有者でもある。

ジョン ・ ニコディモ ( John Nicodemo )
NFLシニアコンサルタント
アメリカ国内でも、最も優れたデータ・リーダーの一人であり、アメリカ、カナダ、そして世界各地のデータ・コンテンツ・チームのマネジメントに従事。 米国ダン・アンド・ブラッドストリートをはじめロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)など、大手企業でデータ管理チームを率い、世界トップクラスの企業からグローバルデータ戦略やソリューションに関する依頼を受ける。 現在は、米国ナショナル・フットボール・リーグ(NFL)のシニアコンサルタントとしてファン・インテリジェンスとデータ共有のエコシステムを全面的に刷新する際のアドバイザーとして従事している。
©️Copyright Compliance Data Lab, Ltd. All rights reserved.
掲載内容の無断転載を禁じます。
今回は、MDMとゴールデンレコードに関するシリーズ「そのゴールデンレコード、実は違った?」の4回目です。前回の記事では、MDMデータについて、そしてゴールデンレコードが良くも悪くも多くのデータ管理体制にとって重要であることについて、幅広く論じてきました。
前回の記事(https://c-datalab.com/ja/blog/idr-matching_20240126)では、ゴールデンレコードは通常、マスターデ ータ管理(MDM)システムにおけるエンティティ(顧客など)の「ベストビュー」であることを説明しました。
マスターデータ管理(MDM)は「データの中の真実を見極める」訓練と言えます。 これ、とても真面目な話なんです! これは以前の記事(https://c-datalab.com/ja/blog/idr-matching_20240222)でも触れています。...