データ管理
現代の日本の金融機関が直面する5つの実務的データ課題(前編)
日本の金融機関が直面するデータ品質の課題は、表記の違いにとどまらず、コンプライアンスや制裁対応に大きな影響を与えます。本記事では、全2回シリーズの第1回として、半角カタカナやカタカナ表記の不一致といった日本特有の問題が、業務効率の低下や誤検知を招く理由を実務の視点から解説します。
金融機関が直面するデータ品質課題の後編。企業名に含まれるノイズ、市町村合併による住所の陳腐化、旧字体といった、実務で頻発するデータ品質の問題がコンプライアンスリスクに及ぼす影響を解説します。制裁スクリーニングの精度向上に不可欠な、高度なクリーニングと名寄せの手法をご紹介します。
前編では、当社が日本各地の商用データを扱う中で特に多くに見られた「5つの代表的なデータ課題」のうち、次の2つを取り上げました。

本記事では、残り3つの課題を取り上げます。
3. 「ノイズ」多い企業名
4. 変動しやすい住所データ
5. 旧字体(古い漢字)の残存
この現象は、企業名の項目に余分な情報が含まれているケースを指します。余分な情報の例としては、本来の正式名称には含まれない支店名、代表取締役の氏名、さらには代理店情報などが挙げられます(例えば、顧客情報レコードの同一フィールドに保険代理店名と被保険者名が併記されているケースで、これは非常によく見られる実務慣行です)。結果として、1つの企業名フィールドの中に事実上2つの企業名が含まれていたり、企業の正式名称とその注記が混在して記録されていたりします。このようなデータを厳密に評価しようとする事業者(例えば、直接の取引相手だけでなく、関与する代理店や仲介者の制裁スクリーニングをしたい企業)は本来、少なくとも次の2点を満たす必要があります。(a) 「混在」が発生していることを把握できること、そして (b) どの主体(エンティティ)が自社にとって重要なのか(あるいは両方とも重要なのか)を選択できることです。
このような状態を放置すると、記録された企業名が実際の正式名称と一致しないため、データ品質の問題が生じます。制裁リストや規制当局のウォッチリストは通常、支店名・役員名・仲介情報などを含めず、法的な正式名称のみを記録することが多いからです。結果として、レコード間の不整合が増え、企業の正確な特定・照合が難しくなり、データベース内で重複や分断(同一企業が別レコードとして散在すること)が起こりやすくなります。統合・レポーティング・分析の信頼性が低下することで、制裁対象者を検知するためのスクリーニング精度にも影響が及びかねません。これを防ぐには、より高度なクリーニング(不要情報の除去)と正規化(表記の統一)を行い、照合に使うデータの正確性を高めることが有効です。
このような場面で当社は、利用するデータを可能な限り「きれいな状態」に保つために、高度なデータ検証プロセスを用います。初期のデータ衛生テストに通らないデータは、後続処理に流さず、追加のクリーニング(場合によっては目視確認)へ迂回させ、その後で下流工程に投入します(図1)。
この分野におけるベストプラクティスは、多くの場合次の組み合わせです。まず、ルールに沿って機械的に整える「データ衛生(data hygiene)」の処理があります。次に、NLP(自然言語処理)で、ルールだけでは拾いきれないパターンや表現のゆれを見分けます。さらに、人手での確認・修正も取り入れます。重要なのは、人が直した内容をシステム側に反映させ、次回以降の判定精度を上げていく“好循環”を作ることです。当社では、顧客の目的(ユースケース)、データ量、求められる処理スピード(納期)に応じて、これらの手法を使い分けています。
行政改革や境界変更の影響をうけて、日本の住所は時間とともに大きく変化してきました。直近の大きな動きとしては、1999年から2006年にかけて行われた全国的な市町村合併「平成の大合併」があります。これは市町村数を約3,200から約1,700へとほぼ半減させ、都市・町村名やその物理的な境界に広範な変更をもたらしました。こうした合併は、日本の住所データが陳腐化しやすい要因になっています。
平成の大合併後も変化は続いています。たとえば比較的最近の市町村合併として、下都賀郡に属していた岩舟町が2014年に栃木市へ編入された例があります。顧客住所が岩舟町のまま更新されていない場合、その住所は地図ツールや公式データベースで正しく照合できなくなる可能性があります。その結果、位置情報の照合に失敗したり、郵便物が返送されたり、本人確認時にコンプライアンス上の問題が生じたりする可能性があります。
長期間保存される住所データは、意識して更新しない限り、すぐに古くなります。たとえば、市町村合併などで自治体名や区名が変わっても、レガシーシステムには旧名称のまま残ることがあります。すると、同じ場所なのに「別の住所」と判断され、旧住所と現住所がそれぞれ別レコードとして登録されてしまい、顧客データの重複につながります。こうした重複を防ぐためにも、顧客情報を定期的に見直し、最新の状態に保つことが重要です。
また、日常的な転居や事務所移転も住所データを複雑にします。移転先が同じ市内であっても、建物名や丁目・番地、区名など住所の一部が変わるため、表記が少し違うだけで別住所として扱われてしまうことがあります。
当社では、ファジーマッチング(あいまい一致)に補助情報(例:郵便番号、都道府県、市区町村)を組み合わせ、住所を複数の階層で評価します。 これにより、上記のような理由で公式データベースと一致しない古い住所であっても、顧客識別と住所データの検証を行えるようにしています。
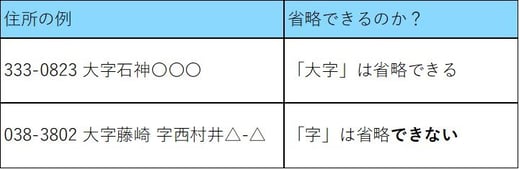
行政改革による住所変更と同様に、歴史的な住所表記のゆれも、金融機関にとって重要なデータ品質上の課題を生み出しています。かつて地域を細分化するために用いられていた「大字・字・小字」といった古い区分表記は、現在でも住所データの中に不均一に残っています。特に地方部や歴史的に区分が定義されている地域では、現代でも見られます。現代の運用では、自治体によってこれらの要素が「完全に記載される」「省略される」「略記される」といった差が生じます。日本郵便の案内では、正しい郵便番号が記載されている場合、町名の前の「大字」や「字」を省略できるとされています。ただし、「字」が「大字」に続く場合、その「字」は省略できません(図2)。加えて、このルールはあくまで郵便配達に関する扱いであり、不動産登記や契約書など正式な法的文書や公式文書では、これらを省略せずに記載する必要があります。
図2: 日本郵便の大字・字の省略に関するガイダンスの例
この表記の不一致により、住所文字列に細かな差が生まれます。その結果、完全一致を前提とした突合処理や、都市部の新しい住所表記を想定した仕組みでは、処理が破綻することがあります。金融機関にとっては、顧客確認での照合不一致、郵送物の誤配・返送といった業務ロス、そして同一顧客が重複登録されることによるデータの膨張につながり得ます。具体的には、実体は同じ顧客なのに、「大字」「字」など旧来の表記要素の有無だけが違う住所として扱われ、複数の住所にひも付いた別レコードが作られてしまう状況です。
当社では、こうした旧来要素の存在を前提に、ファジーマッチング(あいまい一致)とジオコーディング(位置情報付与)を組み合わせたデータ検証・照合プロセスを用い、住所表記の不一致に伴うリスクを低減しています。
業務効率の観点に加え、高品質なデータは現代のコンプライアンス体制を支える基盤です。金融機関がレガシーシステム、複数言語、変化し続ける規制・基準のもとで業務を行う中、顧客データの不整合は、そのままコンプライアンス上のリスクにつながりかねません。文字コードの違い、表記のゆれによるあいまいさ、企業名の不正確さ、住所データの不一致といった問題は、顧客や取引先を確実に識別する能力を弱めてしまいます。
これらの課題に共通する要点は、「マッチング精度こそがデータ品質を測る本質的な指標である」ということです。記録を一貫して照合できなければ、スクリーニング結果の管理は難しくなり、誤検知が増え、真に対応すべきリスクの特定も困難になります。時間がたつにつれデータが劣化し、業務効率が下がるだけでなく、金融機関が取引先や規制当局に対して適切な管理態勢を示す力も弱まってしまいます。
当社は、金融機関におけるコンプライアンスと商用データ活用の双方を最適化するため、データ品質の改善に取り組んでいます。お客様や業界関係者、行政機関の皆さまが直面しているデータ品質の課題、そして日本の商用データ環境全体の効率性・有効性を高めるために業界として何ができるのか、皆さまと共に考えていければ幸いです。
著者のご紹介
ウオリック・マセウス

ウオリック・マセウス(Warwick Matthews)
最高技術責任者 兼 最高データ責任者
複雑なグローバルデータ、多言語MDM、アイデンティティ解決、「データサプライチェーン」システムの設計、構築、管理において15年以上の専門知識を有し、最高クラスの新システムの構築やサードパーティプラットフォームの統合に従事。 また、最近では大手企業の同意・プライバシー体制の構築にも携わっている。
米国、カナダ、オーストラリア、日本でデータチームを率いた経験があり、 最近では、ロブロー・カンパニーズ・リミテッド(カナダ最大の小売グループ)および米国ナショナル・フットボール・リーグ(NFL)のアイデンティティ・データチームのリーダーとして従事。
アジア言語におけるビジネスIDデータ検証、言語間のヒューリスティック翻字解析、非構造化データのキュレーション、ビジネスから地理のIDデータ検証など、いくつかの分野における特許の共同保有者でもある。
日本の金融機関が直面するデータ品質の課題は、表記の違いにとどまらず、コンプライアンスや制裁対応に大きな影響を与えます。本記事では、全2回シリーズの第1回として、半角カタカナやカタカナ表記の不一致といった日本特有の問題が、業務効率の低下や誤検知を招く理由を実務の視点から解説します。
AIの導入には、実務的なガバナンスの構築が不可欠です。本稿では、南アフリカ政府の政策撤回やAIによるデータ削除など、制御逸脱が招いた最新の3事例を厳選して分析します。ハルシネーションや指示無視といったリスクを詳解し、今講ずべき実効的な監督体制と防衛策について考えます。
AI導入が急速に進む中、金融機関は料金モデル変更によるコスト増加リスク、データガバナンスの複雑化、国内データ保管要件への対応など、新たな課題に直面しています。本記事ではAIレディネスの観点から、企業がAIを効果的かつ安全に活用するために押さえるべき実務上の留意点と対応の方向性について解説します。